RAG Is Fixing AI's Trust Problem
tl;dr
- RAG works: RAG (Retrieval-Augmented Generation) connects AI models to real data sources, dramatically reducing hallucinations
- Hallucinations are expensive: Global business losses from AI-generated errors reached $67.4 billion in 2024, making accuracy a business imperative
- The market is surging: The RAG market is projected to grow from $1.94 billion in 2025 to $9.86 billion by 2030 at a 38.4% CAGR
- RAG is not a silver bullet: Even purpose-built RAG tools in legal research still hallucinate 17–33% of the time, according to Stanford research
- Implementation strategy matters: Organizations that treat RAG as an architecture problem—not a feature toggle—see 30–60% reductions in content errors
Ask an AI model about your company's return policy and it will give you an answer that sounds perfectly reasonable. Confident tone, clear structure, authoritative language. One problem: the policy it describes does not exist. The model made it up.
This is AI hallucination, and it is one of biggest barriers between where enterprise AI stands today and where businesses need it to be. Large language models are statistical prediction engines. They generate the most probable next word based on patterns in their training data. They do not retrieve facts. They do not check sources.
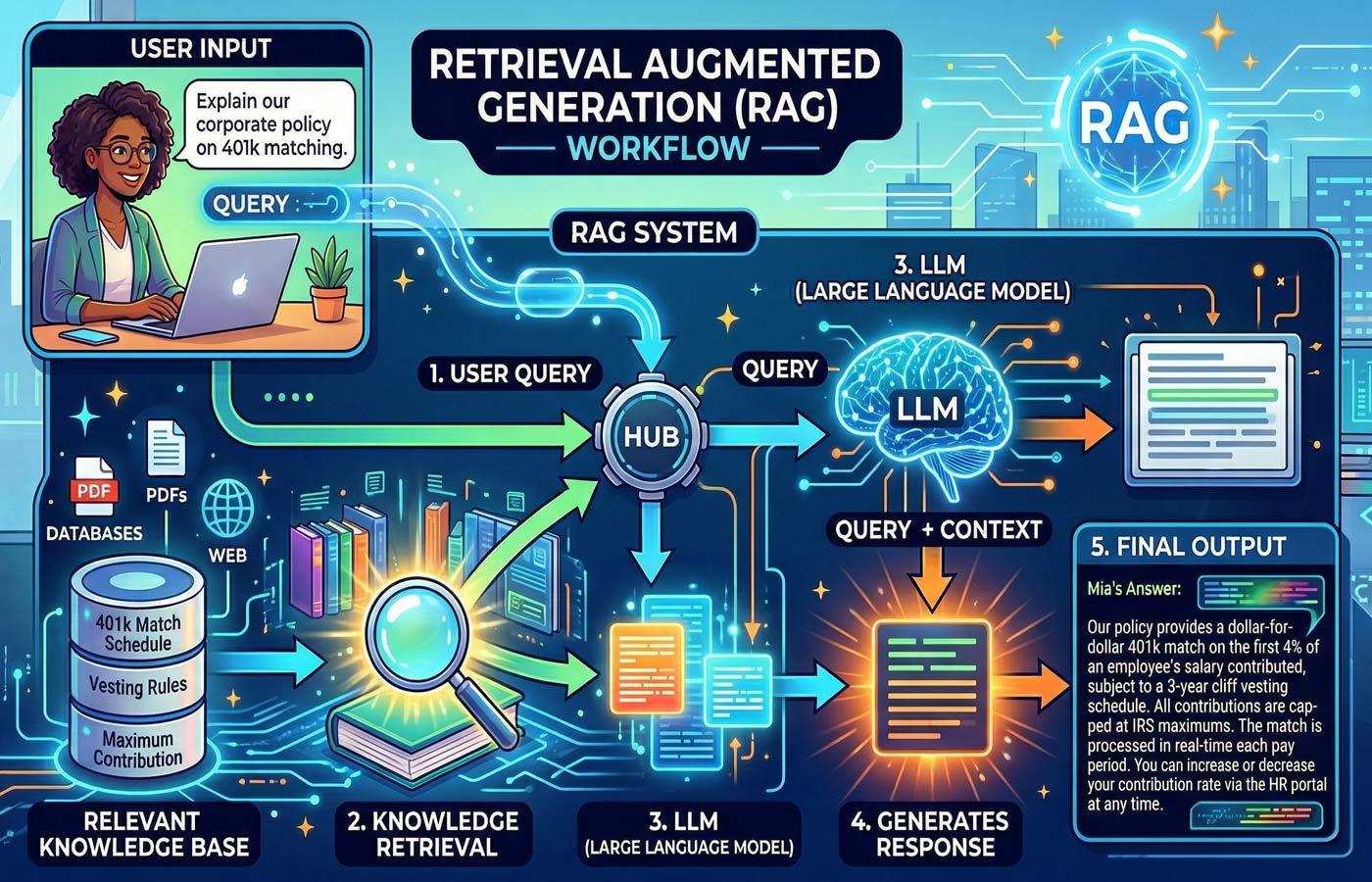
Retrieval-augmented generation (RAG) is an architectural pattern designed to solve this. Instead of asking a model to answer from memory, RAG retrieves relevant documents from a trusted knowledge base and hands them to the model before it generates a response. Think of it as giving AI an open-book exam instead of asking it to recall everything from training. This article breaks down how RAG works, what the data says about its effectiveness, where it still falls short, and what you should know before investing.
How RAG Works
The core idea behind retrieval-augmented generation is straightforward. Instead of relying on what a model "learned" during training or even its ability to search the internet, RAG provides the model with specific and relevant information retrieved at the moment a prompt is processed.
A RAG system operates in two phases. First is the retrieval phase. When a user asks a question, the system searches a knowledge base, which could be anything from internal policy documents to product manuals to regulatory filings, and pulls back the most relevant information. Second is the generation phase. The retrieved information is passed to the language model along with the original prompt and then the model generates its response.
The practical implications of this architecture are significant. Because RAG-enabled systems access information that did not exist when the model was trained, or the model simply doesn't have access to, organizations can update their knowledge bases daily or in real-time, and those updates are immediately available through RAG without any model retraining. As well, users can trace answers back to specific source documents, creating a level of transparency that standalone models can't provide.
Hallucination by the Numbers
Before understanding the solution, it helps to understand the problem. Hallucinations are not occasional edge cases. They are a structural feature of how large language models operate.
The Vectara Hallucination Evaluation Model (HHEM) Leaderboard, one of the most widely referenced benchmarks in the industry, has tested over 100 language models on document summarization tasks. Even the best-performing models are not immune. And, while some models hallucinated in nearly one out of every three responses.[2] And that is on the constrained task of summarizing a document the model has already been given.
When models face open-ended factual questions without source material, the numbers get worse. In the legal domain, a landmark Stanford study found that general-purpose chatbots hallucinated between 58% and 82% of the time on legal queries, inventing case citations, fabricating statutory provisions, and confidently mischaracterizing court rulings.[4]
Global losses attributed to AI hallucinations reached $67.4 billion in 2024.[3] When 47% of enterprise AI users report making at least one major business decision based on hallucinated content, this stops being a technical curiosity and becomes a boardroom-level risk.[3]
RAG and Hallucination Reduction
RAG is consistently identified as the most effective technique for reducing AI hallucinations in production systems. But the numbers vary depending on the implementation and the domain.
At the broad level, research suggests that well-implemented RAG systems reduce hallucinations by up to 71%.[3] One study evaluating twelve RAG variants on clinical decision support found that reflective RAG architectures reduced hallucination rates by nearly 95% on medical vignettes.[7]
These are meaningful improvements. When researchers evaluated RAG-powered legal tools from major providers like LexisNexis and Thomson Reuters, they found that RAG did reduce errors compared to general-purpose models. But the Lexis+ AI system still produced incorrect information more than 17% of the time, while Westlaw's AI-Assisted Research hallucinated on roughly 33% of benchmarking queries.[4]
The takeaway is not that RAG fails. It is that RAG reduces hallucinations without eliminating them. Understanding this distinction is critical for when building an AI strategy around RAG.
Why RAG Still Hallucinates
If RAG connects the model to real documents, why does it still get things wrong?
- Retrieval Failures: The most straightforward failure: the system retrieves the wrong documents. Most RAG systems identify relevant documents based on textual similarity, but relevance in complex domains is not always about similar words. In legal research, for example, a case might be textually similar but jurisdictionally irrelevant or factually distinguishable.
- Generation Failures: Even with the right documents retrieved, the model can still misinterpret, over-generalize, or selectively ignore the provided context. This is particularly problematic for queries where the model has strong prior beliefs from training that conflict with the retrieved evidence.
- Data Quality Issues: A RAG system is only as reliable as its knowledge base. One comprehensive review found that data source problems, query ambiguity, and context conflicts between retrieved documents were among the most persistent contributors to hallucinations.[9]
Enterprise Adoption
The global RAG market is estimated at $1.94 billion in 2025 and projected to reach $9.86 billion by 2030, growing at a compound annual rate of 38.4%.[11] Healthcare and life sciences, financial services, and legal are among the fastest-growing adoption sectors; precisely the domains where incorrect information carries the highest consequences.
Common enterprise RAG use cases include internal knowledge management assistants that surface policies and procedures on demand, customer service systems that retrieve account data and product documentation before responding, compliance monitoring tools that reference current regulatory guidance, and research assistants that synthesize information across large document collections.
Building RAG That Works
The gap between RAG implementations that deliver real value and those that disappoint comes down to architecture, data discipline, and governance.
- Start with Quality Data: Clean, well-structured, current documents with good metadata produce better retrieval results. Organizations that invest in document hygiene before deploying RAG consistently report better outcomes than those that point a retrieval system at an unstructured data lake and hope for the best.
- Combine Strategies: The most effective RAG deployments do not rely on retrieval alone. They combine multiple approaches. The MEGA-RAG framework's success in healthcare, for instance, came from combining retrieval, keyword-based retrieval, and biomedical knowledge graphs; not any single technique in isolation.[6]
- Keep Humans in the Loop: When people must verify every response, it undercuts the efficiency gains that the AI tools are supposed to provide.[4] The practical middle ground is designing systems that surface their confidence level and source citations alongside every answer, making verification faster rather than unnecessary.
- Release, Measure, and Iterate: Identify two or three high-value use cases with large document volumes, frequently changing information, and a current pain point around accuracy or search quality. Deploy a pilot, measure the results, and expand based on what works.
Final Thoughts
Today, RAG represents the most practical, production-ready approach to making AI systems more accurate. The data supports this: up to 71% reduction in hallucinations, measurable productivity gains, and a maturing ecosystem of tools and platforms. But RAG is a mitigation strategy, not a cure. Hallucinations are inherent to how language models work, and no retrieval architecture eliminates them entirely.
To extract the most value from RAG, treat it as an architecture and governance problem rather than a plug-and-play feature. Invest in data quality, layer multiple verification strategies, keep humans in the loop, and measure outcomes rigorously. Build systems with the right guardrails, the right data foundations, and the right expectations.
The RAG market is projected to reach nearly $10 billion by 2030 for a reason; this technology works. And it works best when implemented with a clear understanding of what it can and cannot do.
References
- AI Hallucination Statistics: Research Report 2026 — Suprmind (citing MIT research, January 2025)
- AI Hallucination Report 2026: Which AI Hallucinates the Most? — AllAboutAI (citing Vectara HHEM Leaderboard and Google 2025 research)
- AI Hallucination Rates Across Different Models 2026 — About Chromebooks (citing Deloitte, Forrester Research, and Vectara data)
- AI on Trial: Legal Models Hallucinate in 1 out of 6 (or More) Benchmarking Queries — Stanford HAI (Magesh, Surani, Dahl, Suzgun, Manning & Ho, 2025)
- Retrieval-Augmented Generation (RAG) — Business & Information Systems Engineering, Springer Nature (2025)
- MEGA-RAG: A Retrieval-Augmented Generation Framework with Multi-Evidence Guided Answer Refinement for Mitigating Hallucinations of LLMs in Public Health — Frontiers in Public Health (Xu, Yan, Dai & Wu, 2025)
- Evaluating Retrieval-Augmented Generation Variants for Clinical Decision Support: Hallucination Mitigation and Secure On-Premises Deployment — MDPI Electronics (2025)
- ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability — ICLR 2025 Spotlight
- Hallucination Mitigation for Retrieval-Augmented Large Language Models: A Review — MDPI Mathematics (2025)
- The State of AI: Global Survey — McKinsey & Company (2025)
- Retrieval-augmented Generation (RAG) Market worth $9.86 billion by 2030 — MarketsandMarkets (2025)
- The Context Crisis: Why AI Projects Are Failing And How To Fix It — Forbes (2025)